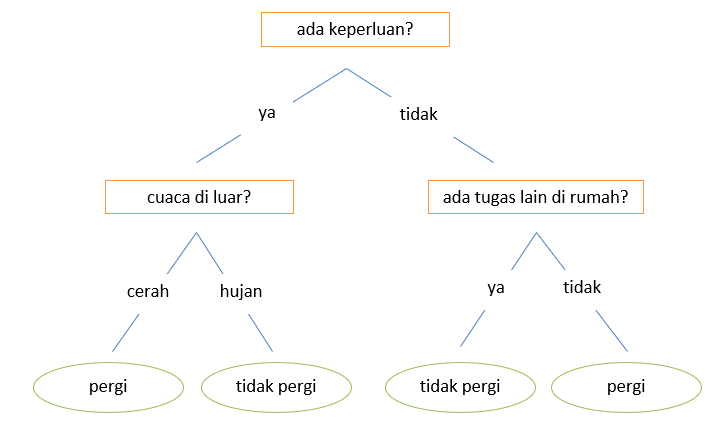
Root node
Root node merupakan node yang paling tinggi di dalam struktur pohon dan tidak memiliki parent node. Node ini merupakan atribut global dan mewakili keseluruhan sampel. Root node bisa memiliki dua atau lebih sub-node dan ditentukan berdasarkan hasil dari Attribute Selection Measure (ASM).
Sub-tree / Branch
Sub-tree / Branch adalah sub-bagian atau cabang dari keseluruhan pohon. Struktur di dalam kotak pada gambar sebelumnya merupakan contoh dari sub-tree.
Baca juga: Cara Mengambil Nama Kolom di Dataframe
Decision node
Decision node merepresentasikan fitur-fitur atau atribut-atribut di dataset dan digunakan untuk membuat keputusan.
Leaf node
Leaf node merupakan output atau hasil dari keputusan yang tidak memiliki cabang lebih lanjut.
Parent and child node
Sebuah node yang memiliki cabang lagi disebut dengan parent node, sedangkan node cabang (sub-node) yang dimaksud disebut dengan child node dari parent node tersebut.
Pruning
Pruning dalam decision tree berarti menghapus sebuah sub-tree yang berlebihan dan tidak berguna dan menggantinya dengan leaf node. Teknik ini berfungsi untuk membantu mencegah overfitting pada data latih sehingga model bekerja dengan baik pada data baru (unseen data)
Information gain
Information gain dapat diartikan sebagai ukuran seberapa banyak sebuah fitur memberikan informasi tentang sebuah kelas/target. Ini merupakan salah satu metode Attribute Selection Measure (ASM) untuk menentukan seberapa baik sebuah fitur untuk dijadikan decision node.
Baca juga: Apa Itu Bias dan Variance di Machine Learning?
Entropy
Entropy adalah metrik teori informasi yang digunakan untuk mengukur ketidakmurnian (impurity) atau ketidakpastian (uncertainty) di dalam sebuah kelompok pengamatan. Entropy menentukan bagaimana decision tree membagi data.