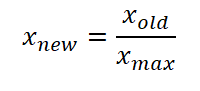Pada tabel di atas, kita lihat bahwa perbedaan rentang nilai dari variabel terlihat sangat jauh. Variabel umur memiliki kisaran nilai dari 0 sampai 100, sementara variabel gaji berkisar dari 0 sampai 500.000. Ini berarti variabel gaji bernilai sekitar 1000 kali lipat lebih besar dibandingkan variabel umur.
Baca juga: 3 Contoh Penerapan Data Formatting dengan Pandas
Ketika kita melakukan analisis lebih jauh seperti misalnya pemodelan menggunakan linear regression, variabel gaji akan lebih mempengaruhi hasil dikarenakan nilainya yang lebih besar. Model regresi linear akan menimbang gaji dengan lebih berat dari pada umur.
Untuk menghindari kondisi semacam ini, kita bisa menormalisasi dua variabel tersebut menjadi nilai yang memiliki rentang yang sama yaitu dari 0 sampai 1 seperti pada tabel di sebelahnya.