Binning adalah sebuah proses untuk mengelompokkan data ke dalam bagian-bagian yang lebih kecil yang disebut bin berdasarkan kriteria tertentu. Binning data merupakan salah satu teknik praproses data yang digunakan untuk meminimalisasi kesalahan dalam pengamatan serta terkadang dapat meningkatkan akurasi dari model prediktif.
Binning biasanya digunakan untuk mengelompokkan data numerik menjadi beberapa bin agar sebaran data lebih mudah dipahami. Misalnya kita dapat mengelompokkan fitur “usia” menjadi [0-5], [6-10], [11-15], [16-20], [20-25], dan seterusnya.
Baca juga: Cara Memilih Algoritma Machine Learning
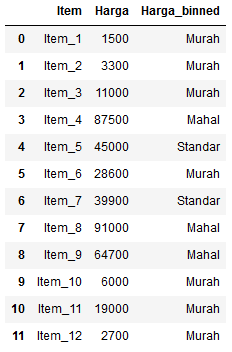
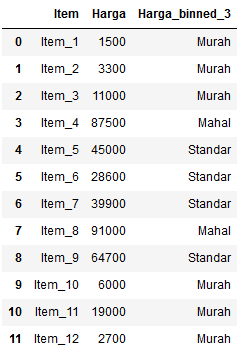
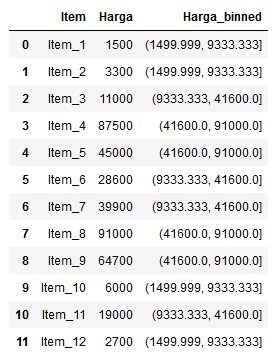
Contoh lain misalnya sebuah data yang memiliki fitur “harga” dengan kisaran 1000 hingga 99000. Kita bisa membagi harga tersebut menjadi tiga bin, “murah”, “standar”, dan “mahal” dengan batas tertentu.
Di Python, ada beberapa cara yang dapat dilakukan untuk membagi data menjadi beberapa bin.