Di dalam mengerjakan projek data science atau data analisis terkadang data yang ada tidak memiliki header atau nama kolom yang tidak sesuai sehingga dapat membuat kita kesulitan untuk memahaminya. Di Pandas Python, ada beberapa cara yang dapat dilakukan untuk mengatasi hal tersebut.
Sebelum mulai membahas satu per satu cara yang dapat digunakan untuk menambahkan header pada dataframe di Python, saya akan membuat beberapa list terlebih dahulu yang akan digunakan sebagai data untuk membuat dataframe nantinya.
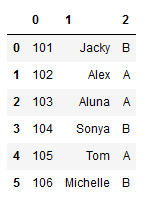
Misalnya kita memiliki tiga list seperti di bawah ini.
Output dari kode di atas adalah dataframe dengan 3 kolom dan 6 baris dengan nama kolom default seperti di bawah ini.
Menambahkan header saat membuat Dataframe
Cara yang pertama untuk menambahkan header atau nama kolom adalah langsung pada saat membuat dataframe. Anda dapat melakukannya dengan menambahkan parameter ‘columns’ di methodDataFrame() seperti pada potongan kode di bawah ini.
Jika Anda menggunakan dataset yang berekstensi CSV atau lainnya, Anda juga dapat langsung menambahkan header saat load data. Untuk menambahkan header saat membaca file ke dataframe Python, Anda dapat menggunakan parameter ‘names’ seperti di bawah ini.
Dalam hal ini, saya telah menyimpan dataframe yang telah dibuat sebelumnya menjadi filestudent_eg.csv. Output yang dihasilkan dari kode program di atas sama dengan yang sebelumnya.
Menggunakan dataframe.columns
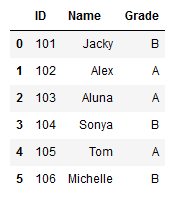
Cara selanjutnya untuk menambahkan header pada dataframe yaitu dengan menggunakan dataframe.columns. Perhatikan kode program di bawah ini.
df = pd.DataFrame([*zip(list1, list2, list3)])
df.columns = ['ID', 'Name', 'Grade'] df
Anda dapat membuat dataframe ataupun membaca file terlebih dahulu, setelah itu mengaplikasikan dataframe.columns untuk menambahkan header atau nama kolom. Pada potongan kode di atas, saya menggunakan df.columns karena dataframe saya dimasukkan dalam variabel df.
Output:
Menggunakan method Rename
Anda juga dapat menggunakan methodrename() untuk mengubah nama kolom. Perhatikan contoh berikut.
Pada parameter columns, Anda dapat membuat dictionary dimana key-nya adalah nama kolom awal yang ingin diganti, dan value-nya adalah nama kolom baru yang diinginkan.
Output:
Menambahkan header tanpa menghapus yang sebelumnya
Adakalanya kita ingin mempertahankan nama kolom awal, namun kita juga ingin menambahkan nama kolom baru untuk memperjelas isi kolom tersebut. Jika seperti itu, Anda dapat menggunakan MultiIndex untuk membuat lebih dari satu header. Caranya seperti di bawah ini.
Nama kolom awal adalah ‘x’, ‘y’, ‘z’ sedangkan kolom baru adalah ‘ID’, ‘Name’, ‘Grade’. Outputnya seperti di bawah ini.
Semoga bermanfaat!
Jika Anda yang sedang belajar data science atau mengolah data dengan bahasa pemrograman Python namun masih suka bingung menulis kode Python-nya, kami telah menyusun Paket E-modul Python Data Science yang didesain khusus untuk pemula dengan penjelasan bahasa Indonesia yang lengkap untuk setiap blok kode-nya. Dapatkan sekarang juga dengan klik di sini!