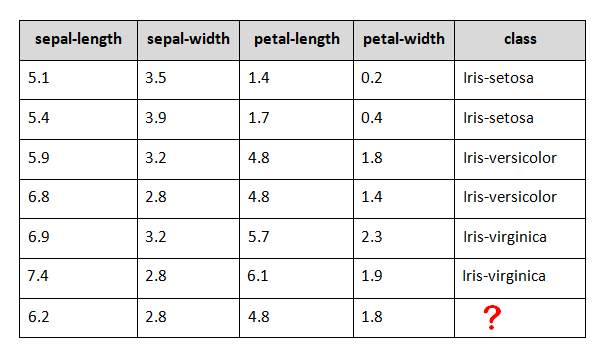
Gambar di atas saya buat berdasarkan dataset Iris yang sudah sangat populer di kalangan data science learners yang dapat diakses disini.
Pada gambar di atas, bagian kotak merah merupakan inputnya atau variabel yang akan diamati, sedangkan bagian kotak kuning adalah outputnya.
Masih belum paham? Baiklah. Intinya, supervised learning itu jika sebuah dataset sudah memiliki target class yang menjadi outputnya.
Misalnya pada dataset Iris di atas, kita sudah tahu bahwa ada tiga kategori yang menjadi target class. Jadi nantinya jika kita masukkan data input baru, outputnya sudah pasti adalah salah satu dari tiga kategori tersebut, yaitu Iris-setosa, Iris-versicolor, atau Iris-virginica.
Baca juga: 3 Metode Normalisasi Data di Pandas Python
Seperti telah disinggung sebelumnya, algoritma supervised learning juga digunakan untuk menyelesaikan masalah regresi atau masalah yang outputnya adalah bilangan kontinu. Contoh permasalahan regresi diantaranya memprediksi harga mobil, nilai mahasiswa (dalam angka), dan sebagainya.
Lalu bagaimana caranya kita “mengajari” sebuah model machine learning agar menghasilkan output yang akurat?