Encoding adalah salah satu tahap praproses data sebelum diproses dengan algoritma machine learning. Dalam mengerjakan projek data science ataupun machine learning, kita akan sangat mungkin menemukan satu atau beberapa fitur yang bertipe kategori, misalnya ‘Sangat Baik’, ‘Baik’, ‘Tidak Baik. Nah, komputer tidak dapat memproses data bertipe kategori sehingga kita harus mengubah data tersebut menjadi berbentuk bilangan. Proses ini disebut dengan encoding.
Apa itu One-Hot Encoding dan kenapa perlu dilakukan?
One-Hot encoding adalah salah satu metode encoding. Metode ini merepresentasikan data bertipe kategori sebagai vektor biner yang bernilai integer, 0 dan 1, dimana semua elemen akan bernilai 0 kecuali satu elemen yang bernilai 1, yaitu elemen yang memiliki nilai kategori tersebut.
Perhatikan contoh berikut. Misalnya kita memiliki data nama kota beserta ID-nya seperti di bawah ini.
Dalam prakteknya menggunakan Python, banyak algoritma machine learning yang tidak dapat memproses data kota tersebut karena bertipe kategori. Untuk memprosesnya, kita dapat mengubah fitur ‘City’ tersebut menjadi bilangan dengan one-hot encoding.
Setiap kategori pada fitur ‘City’ akan menjadi kolom/fitur baru yang bernilai 0 atau 1. Misalnya, pada kolom ‘Jakarta’ pada indeks dengan ID=100 akan bernilai 1, sementara indeks lainnya akan bernilai 0. Nantinya setelah diterapkan one-hot encoding, data di atas kira-kira akan menjadi seperti di bawah ini.
2 Cara One-Hot Encoding di Python
Ada dua cara yang dapat Anda lakukan untuk mengimplementasikan one-hot encoding di Python, yaitu dengan menggunakan library Pandas dan Scikit-Learn.
One-Hot Encoding menggunakan Pandas
Dalam contoh penerapan one-hot encoding di Python ini, kita akan menggunakan data sederhana yaitu data kota seperti tabel di atas. Pertama, kita buat dataframe-nya terlebih dahulu.
Kolom City pada dataframe df mengandung nilai bertipe kategori, sehingga kita akan menerapkan metode one-hot encoding menggunakan fungsi get_dummies() yang ada di Pandas. Perhatikan kode berikut.
Pada atribut prefix, kita isikan ‘City’ sebagai awalan dari tiap nama kolom yang di-encode. Hasilnya seperti di bawah ini.
One-Hot Encoding menggunakan Scikit-Learn
Kita juga dapat menggunakan OneHotEncoder dari Scikit-Learn untuk menerapkan one-hot encoding di Python. Perhatikan kode berikut.
from sklearn.preprocessing import OneHotEncoder
y = OneHotEncoder(sparse=False) y = y.fit_transform(df[['City']]) df_y = pd.DataFrame(y)
Pertama kita harus import OneHotEncoder terlebih dahulu dari librarysklearn.preprocessing. Kemudian kita buat variabel y yang digunakan untuk menampung hasil encoding.
Lalu di baris selanjutnya, pada variabel y tersebut dilakukan fit_transform() untuk kolom ‘City’ di dataframe df untuk mengubah nilai kategori pada kolom ‘City’ menjadi angka.
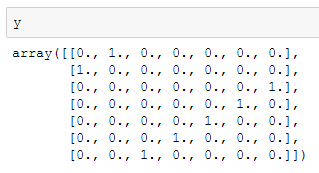
Sampai disini variabel y tersebut masih berupa array. Jika kita print variabel y, hasilnya seperti di bawah ini.
Agar dapat diproses bersama kolom lainnya, variabel y harus dikonversi menjadi dataframe. Pada kode di atas, kita menyimpan dataframe y di dalam variabel df_y.
Output dari df_y adalah sebagai berikut.
Dari gambar di atas, header dataframe hasil one-hot encoding masih berupa bilangan. Untuk dapat memahaminya, kita sebaiknya mengganti header tersebut dengan nilai dari df['City'].
Harap dicatat bahwa, hasil one-hot encoding di atas otomatis terurut dari bawah ke atas, atau A – Z, sehingga kita juga harus men-sortingdf['City'] sebelum dijadikan header. Coba perhatikan kode berikut.
Dari kode di atas, df[‘City’] di-sorting terlebih dahulu dengan fungsi sort_values() dan dimasukkan ke dalam variabel header. Setelah itu barulah kolom dari dataframe df_y diganti dengan header yang ditambahkan awalan ‘City_’ untuk memperjelas bahwa itu adalah hasil encode dari kolom ‘City’.
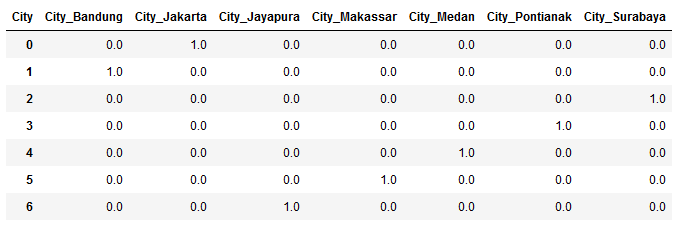
Setelah di-rename, output dari dataframe df_y menjadi seperti di bawah ini.
Setelah itu kita dapat menggabungkannya hasil encoding tersebut dengan dataframe df yang sebelumnya agar dapat diproses sebagai satu kesatuan.
df_join = df.join(df_y)
Output dari df_join seperti di bawah ini.
Semoga bermanfaat!
Jika Anda yang sedang belajar data science atau mengolah data dengan bahasa pemrograman Python namun masih suka bingung menulis kode Python-nya, kami telah menyusun Paket E-modul Python Data Scienceyang didesain khusus untuk pemula dengan penjelasan bahasa Indonesia yang lengkap untuk setiap blok kode-nya. Dapatkan sekarang juga dengan klik di sini!