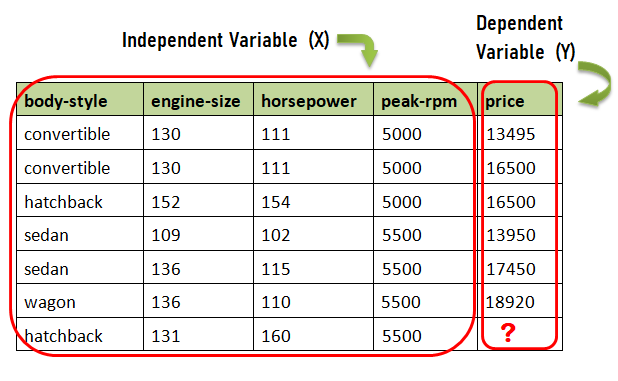
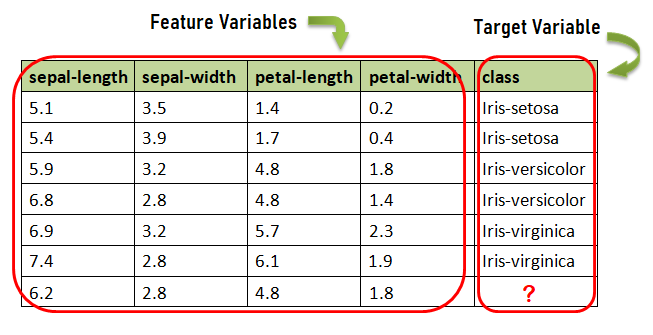
Data di atas terdiri dari beberapa variabel di antaranya body-style, engine-size, horsepower, peak-rpm, dan price. Saya sengaja mengambil beberapa variabel saja sebagai contoh, sementara dataset automobile yang sesungguhnya terdiri dari 26 variabel.
Baca juga: Perbedaan Supervised dan Unsupervised Learning
Dalam regresi, ada dua jenis variabel yaitu Dependent variable dan Independent variable. Variabel dependen adalah variabel yang akan kita prediksi atau pelajari, sedangkan variabel independen adalah variabel yang menjelaskan atau menyebabkan nilai target di variabel dependen.
Variabel independen dinotasikan dengan X, sementara variabel dependen dinotasikan dengan Y. Yang harus diperhatikan dalam kasus regresi adalah nilai dari variabel dependen (Y) harus berupa nilai kontinu, bukan diskrit. Sementara itu untuk variabel independen (X) bisa berupa nilai kontinu maupun kategori, misalnya sedan, hatchback, wagon, convertible.
Untuk memprediksi harga mobil, kita harus membuat model regresi dari data sebelumnya. Setelah model selesai dibuat, kita dapat menggunakannya untuk memprediksi harga mobil menggunakan data baru.