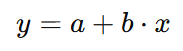Apa ya kira-kira algoritma machine learning paling populer di kalangan pemula yang baru belajar data science atau machine learning?
Machine learning telah menjadi salah satu bidang yang berkembang paling pesat dalam dunia teknologi.
Dari aplikasi sederhana seperti rekomendasi film hingga teknologi kompleks seperti mobil tanpa pengemudi, machine learning memainkan peran utama.
Namun, bagi pemula, memahami algoritma yang mendasari teknologi ini sering kali terasa membingungkan.
Untuk membantu Anda memulai, artikel ini akan membahas lima algoritma machine learning paling populer yang mudah dipahami dan relevan untuk pemula.
Mari kita mulai perjalanan ini dengan membahas setiap algoritma secara sederhana, tetapi tetap mendalam.